🚦 이번 포스팅에서는 〰️
▶️ 힙(Heap) 이란? + 우선순위 큐?
▶️ 힙(Heap) 의 종류
▶️ 힙(Heap) 구현 방법 - 힙의 삭제, 힙의 삽입, 힙의 정렬
📎 힙(Heap)이란?
: 완전 이진 트리의 일종으로 우선순위 큐를 위하여 만들어진 자료구조이다.
여러개의 값들 중에서 최댓값이나 최솟값을 빠르게 찾아내도록 만들어진 자료구조이다.
힙은 일종의 반정렬상태(느슨한 정렬 상태)를 유지하는데,
이는 큰 값이 상위 레벨에 있고 작은 값이 하위 레벨에 있는 정도를 의미한다.
더 직관적인 말로 설명하자면 부모노드가 자식 노드보다 항상 큰 maximum binary tree라고 할 수 있다.
힙은 항상 완전 이진트리의 모습을 지닌다.
✅ 우선순위 큐?
단어 그대로 우선순위가 존재하는 큐이다. 데이터들이 우선순위를 가지고 있어 우선순위가 높은 데이터가 먼저 나가는 형식이다.
우선순위 큐는 배열, 연결리스트, 힙으로 구현이 가능하다.
이중에서 힙으로 구현하는 것이 가장 효율적이다.
우선순위 큐의 사례
- 시뮬레이션 시스템
- 네트워크 트래픽 제어
- 운영 체제에서의 작업 스케쥴링
- 수치 해석적인 계산
📎 힙(Heap)의 종류
1. 최대 힙 (max heap)
- 부모 노드의 값이 자식 노드의 값보다 크거나 같은 완전 이진 트리
- key(parent) >= key(child)

2. 최소 힙 (min heap)
- 부모 노드의 값이 자식 노드의 값보다 작거나 같은 완전 이진 트리
- key(parent) <= key(child)

📎 힙(Heap)구현 방법
- 힙을 저장하는 표준적인 자료구조는 배열이다.
- 배열의 첫번째 인덱스(0)는 최상단 노드(root)이다.
- 특정 위치의 노드 번호는 새로운 노드가 추가되어도 변하지 않는다.
➡️ EX) 루트 노드의 오른쪽 노드의 번호는 항상 3이다.- i번째 왼쪽 자식 노드 = i * 2 + 1
- i번째 오른쪽 자식 노드 = i * 2 + 2
- i번째 노드의 부모노드 = (i - 1) / 2
- 힙에서의 부모노드는 항상 자식노드보다 작거나 같다 or 크거나 같다.
📌 c++ 힙 구현
: 힙의 구현은 STL에서 두가지로 가능하다.
- <algorithm>에 있는 vector을 활용한 make_heap
- <queue>에 있는 priority_queue
❓ 둘의 차이점은 뭘까?
➡️ 둘의 성능 부분에서의 차이점은 없다. 다만, priority_queue는 그저 adapter class로서 heap-related function call이 가능한 클래스이고, make_heap은 vector을 이용해 heap-related function을 다이렉트로 call하는 것이라고 한다.
make_heap을 이용하면 모든 원소에 접근이 가능하고, priority_queue를 이용하면 그 부분은 불가능하다는 차이점도 있다.
결론은, 적절히 사용하고 싶은걸 사용하면 될듯!
1) [ STL Functions - Algorithm header, using Vector ]
- make_heap() : heap 구성, vector의 iterator로 범위 지정함. O(logN)
- push_heap() : heap의 마지막 노드에 원소 추가, O(logN)
- pop_heap() : heap의 최상단 노드(root) pop, O(logN)
- sort_heap() : heap sorting
- is_heap() : 원소 유무
- is_heap_until() : 가장 큰 max_heap인 sub-range를 반환
💡 임의의 순서를 갖는 array가 주어질 때, make_heap의 시간복잡도 = O(N)
2) [ STL priority queue ]
: 일반 STL queue와 사용법이 동일하나, front 대신에 top을 쓴다.
- priority queue는 default=Max heap이다.
- pop시 가장 큰 수부터 내림차순으로 출력된다.
- 오름차순으로 바꾸고 싶다면 greater 인자 삽입하면 된다.
- pair과 함께 많이 사용된다. 비교 순위 = pair의 첫번째 요소로 먼저 비교한 뒤 두번째 요소 비교하는 방식
📌 힙의 삭제
➡️ 우선순위가 가장 높은 루트 노드 (Root Node)가 삭제되어야 한다.
배열로 구현하기 때문에 노드를 할당 해제하는 식이 아닌, 가장 마지막 값으로 대체한 후 힙의 성질에 맞춰서 스와핑하는 식이다.
즉, max heap인 경우 왼쪽 자식과 오른쪽 자식을 모두 비교해 가장 큰 것과 스와핑하면서 자리를 찾아간다.
이처럼 루트로부터 시작해 제자리를 찾기까지의 과정을 Down Heap이라고 하고, 이 과정을 거쳐 힙의 형태가 완성되는 과정을 Heap Rebuilding이라고 한다. (깨알 용어정리)
[요약]
- 루트 노드 삭제
- 삭제된 루트 노드는 마지막 노드로 대체
- 힙 재구성 (Heap Rebuilding)
✅ 힙 삭제의 시간 복잡도
힙의 삭제 과정은 O(logN)이다.
배열의 마지막 노드를 복사하는 것이 O(1), 최악의 경우 leaf node까지 다운힙하는 과정일 경우 O(logN) + 비교할 때마다 왼쪽,오른쪽 다 비교해야하므로 O(logN) = 총 2O(logN)이다.
📌 힙의 삽입
새로 들어온 원소를 마지막 노드에 삽입한 후, 아래에서부터 부모와 비교하여 올라오면서 제자리를 찾는다.
[요약]
- 새로운 원소를 마지막 노드에 삽입
- 아래에서부터 부모노드와 비교하면서 Heap Rebuilding
✅ 힙 삽입의 시간 복잡도
힙의 삽입 과정은 O(logN)이다.
최악의 경우 root node까지 올라가는 과정일 경우 O(logN)이기 때문이다. (힙 삭제와 달리 삽입 작업은 부모노드와 한번만 비교하면 된다.)
📌 힙 정렬
힙 정렬은 힙의 형태를 이용해서 정렬을 하는 것으로, 힙 리빌딩의 반복 과정이라고 볼 수 있다.
내림차순은 [최대 힙의 부모를 삭제->힙 리빌딩] 과정을 반복하면 되고,
오름차순은 [최소 힙의 부모를 삭제->힙 리빌딩] 과정을 반복하면 된다.
힙 정렬의 두가지 방법
- 하향식 힙 구성 (Top-Down)
- 반복적으로 힙에 삽입 작업을 가하는 방법
- 시간 복잡도 = 삽입될 때마다 logN, N개가 삽입되므로 O(NlogN) + 정렬을 위한 힙의 삭제 단계에서 O(NlogN)
➡️ O(NlogN) - 노드를 아래에 삽입한 후, 위로 올라가면서 비교하며 Rebuilding
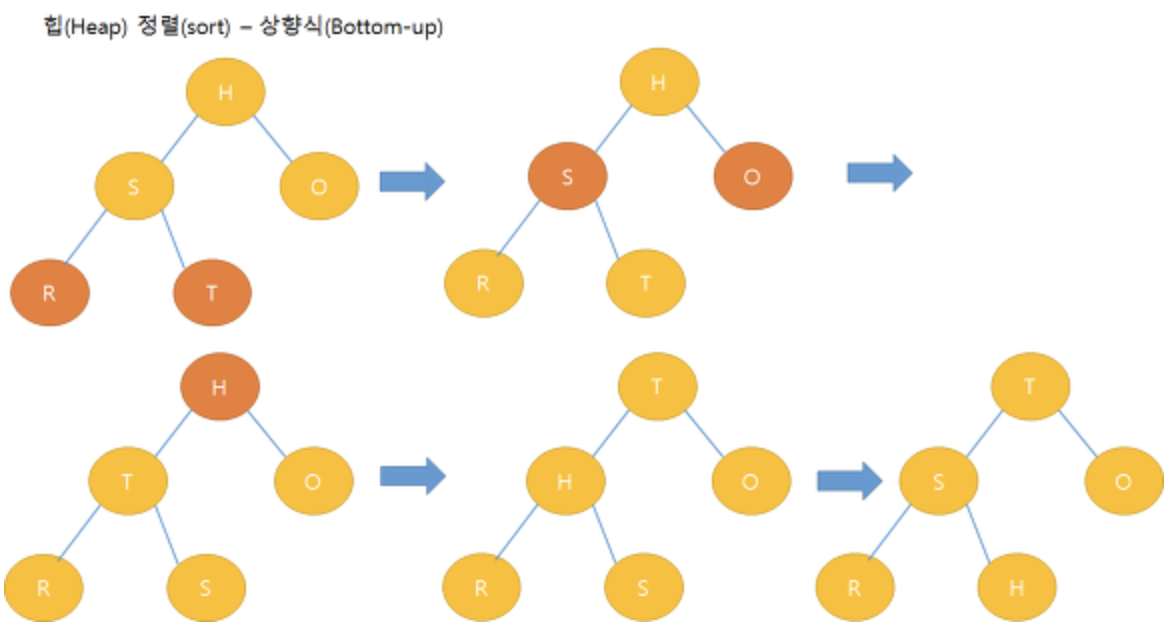
- 상향식 힙 구성 (Bottom-Up)
- 들어오는 키 값의 순서대로 일단 트리를 구성한 후, 힙 구조가 되도록 재조정하는 방법
- 위에서 아래로 내리는 방법으로 Rebuilding
- 검사할때는, 해당 노드와 해당노드의 아래쪽만 검사한다.
- 따라서, leaf node는 그 아래 노드가 없기때문에 아예 비교조차 하지 않는다.
- O(N)에 가까운 시간 복잡도를 가진다.

❓ 힙이 이진 탐색 트리(binary search tree)에 비해 유리한 이유?
➡️ 트리의 높이때문이다.
이진 탐색트리는 균형트리를 유지한다는 보장이 없지만 힙은 반드시 균형트리를 이뤄야 하는 완전 이진트리이기 때문.
🔆 [자료구조] 다른 Posting 보러 가기 🔆
[참고]
https://slenderankle.tistory.com/158
https://gmlwjd9405.github.io/2018/05/10/data-structure-heap.html
'Algorithm > 자료구조' 카테고리의 다른 글
| [자료구조] 그래프(Graph)란? +(인접 리스트vs인접행렬) (0) | 2023.08.11 |
|---|---|
| [자료구조] 맵(Map), 셋(Set) 이란? (0) | 2023.08.09 |
| [자료구조] 트리(Tree)란? (0) | 2023.08.03 |
| [자료구조] Queue란? (+Circular Queue, Priority Queue, Deque) (0) | 2023.07.10 |
| [자료구조] 스택(Stack)이란 (0) | 2023.07.10 |