저번 포스팅에서 BERT 모델에 대해 알아봤다!
이번에는 BERT를 이용해서 네이버 영화 리뷰 데이터를 긍정, 부정 감정분류하는 실습을 해보고자한다.
여러 블로그들을 참고해보며 코드를 작성했고,
특히 Teddy님의 블로그를 많이 참고하였다. (압도적 감사)
처음부터 뚝딱뚝딱 만들 수 있으면 좋겠지만, 이번 실습의 목표는 코드를 뜯어보고 체화시키는 것이기 때문에 욕심 부리지 않기로 했다!
대신, 더 내 코드로 만들어서 점점 성장하는 걸로!!
이번 코드에는 python의 magic method가 많이 나오는데, 한번 정리하면 좋을것같아서 추후 정리예정!!
전체 코드 깃헙 -> 링크
시작해봅시다!!
1. 데이터셋
데이터셋은 github에 올라와 있는 naver sentiment movie corpus를 clone해서 사용해줬다.
데이터 확인해보고 싶은 사람을 위한 -> 링크
2. EDA 및 전처리
1️⃣ 데이터 확인
우선, 데이터 분포도를 봐주고, 데이터가 어떤 형식으로 되어있는지 확인해줬다.
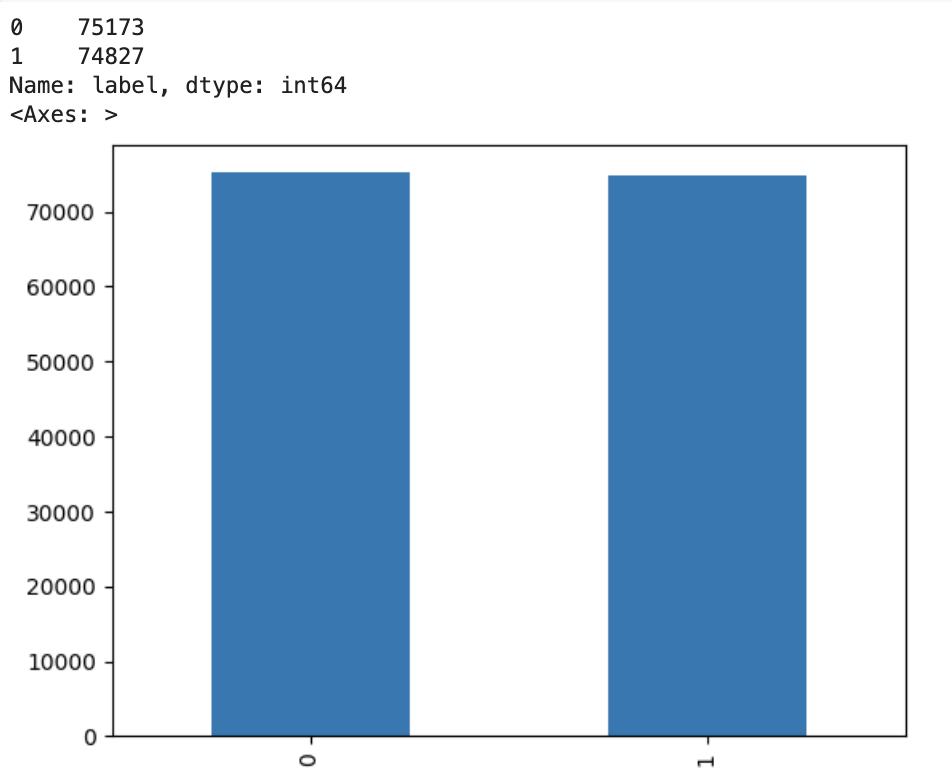
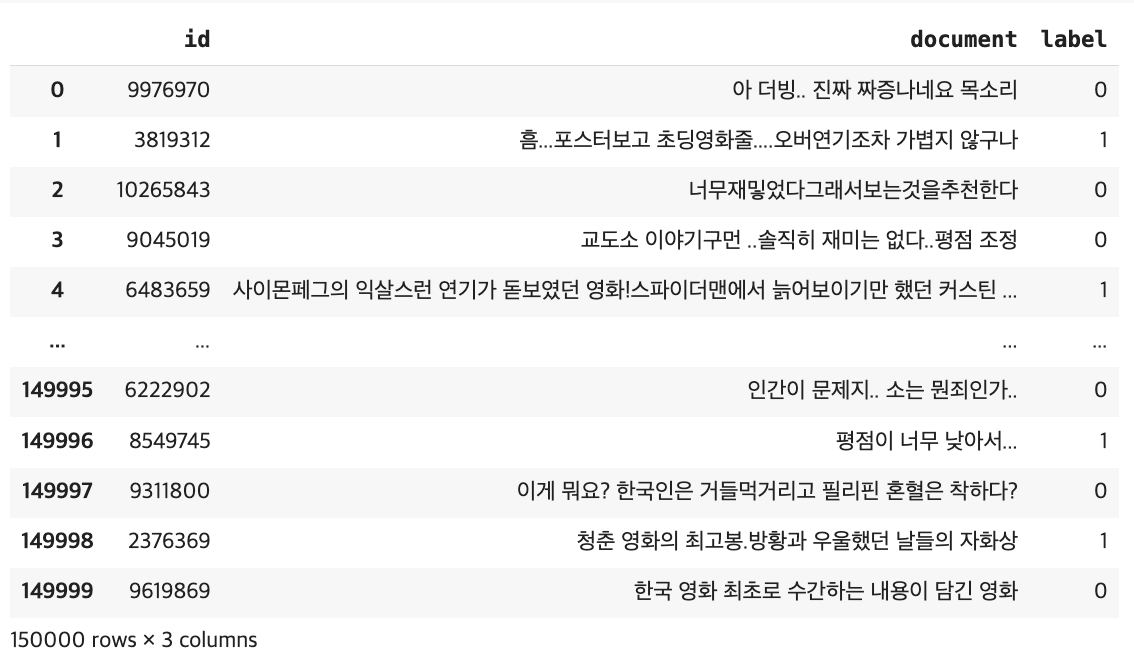
데이터는 {부정리뷰 : 0, 긍정리뷰 : 1}로 레이블링이 이미 되어 있고, 두개의 레이블의 비율이 거의 같음을 확인했다.
col = [id, document, label]로 리뷰 내용은 document에 있음을 확인했고, Id는 필요없으므로 나중에 제거해주도록 한다.
2️⃣ 중복 및 결측치 제거
각 데이터에 결측치를 확인해서 제거해주었고, 중복은 없어서 넘어갔다.

3️⃣ 길이 제한 및 샘플링
길이가 너무 짧으면 예측이 잘 안된다고 해서 5이상의 길이만 남겨주었다.
그리고, 샘플 개수가 150000개로 너무 커서 지금은 연습이니까 train, test 각각 1000개, 500개씩으로 샘플링해주었다.
4️⃣ 토큰화 함수
transformer의 Tokenizer들에 대해서 짧막하게 알아보자!
다 다루지는 못하겠지만, 여기서는 BERT관련 가장 많이 들어봤을법한 3가지에 대해 알아보겠다.
더 자세한 내용에 대해 알고싶다면 공식문서 참조! -> 링크
- BertTokenizer
: Bert모델을 위해 개발된 표준 토크나이저. PreTrainedTokenizer를 상속받는다. - BertTokenizerFast
: BerTokenizer과 동일한 토큰화 방식을 제공하지만 더 빠른 성능과 추가적인 기능을 제공한다. (속도가 1.2~1.5배 빠름)
따라서, 대규모 데이터셋을 처리할 때 시간 효율성이 중요한 경우에 유용하다. - PreTrainedTokenizer
: 다양한 Pre-Trained 모델에 공통적으로 사용되는 범용 토크나이저. 일종의 템플릿으로 볼 수 있다.
즉, 각각의 모델들에 특화되어 개발된 여러 토크나이저들은 PreTrainedTokenizer을 상속받아 특정 모델에 맞게 확장한다.
알아보니, PreTrainedTokenizer을 직접 사용할 수도 있지만 이는 일반적이지 않고, 대부분 구체적인 모델에 맞는 토크나이저를 사용한다고 한다.
따라서, 이번 실습에서 나는 BertTokenizerFast를 사용하도록 하겠다. (BUT) 속도가 빠른 장점이 있으나 성능에 영향을 줄 수 있으니 유의하자!
클래스 형태로 정의해줬는데, 물론 하나씩 풀어서 사용해도 되지만, 나중에 복잡한 데이터 파이프라인 등에서 관리/사용이 쉽도록 체화시키기 위해 진행했다.
BertTokenizerFast로 Huggingface 토크나이저를 생성해주고, sentence는 데이터 'document'부분, label은 데이터 'label'부분을 지정해줬다.
토크나이저 파라미터 조절은 직관적으로 해줬다. 여기서 스페셜 토큰을 잠깐 집고 가자면,
💡 스페셜 토큰(Special Token)이란?
: 토큰화 과정에서 특별한 목적을 가진 토큰으로, BERT에서는 다음과 같은 스페셜 토큰이 자주 사용된다. (아마 익숙할듯)
- [CLS] : 문장의 시작을 나타내는 토큰
- [SEP] : 문장의 끝은 나타내거나 두 문장을 구분할 때 사용하는 토큰
- [PAD] : 길이를 맞추기 위해 사용되는 패딩 토큰
아무튼, 토크나이징 클래스를 구현해줬다.
init으로 객체 초기화를 해주고, 이후 progress bar에 쓸 len과 self[key]값 구해주는 getitem 매직메서드를 구현해줬다.
return 형식은 토큰화된 데이터와 레이블을 반환한다.
이런 return 형식은 DataLoader를 사용하여 데이터를 배치로 처리할 때 유용하다고 한다.
자세한 코드 설명은 주석으로 달아놨다.
import torch
from transformers import BertTokenizerFast
from torch.utils.data import Dataset, DataLoader
# transformer tokenizer 공식 문서
# https://huggingface.co/docs/transformers/main_classes/tokenizer#transformers.PreTrainedTokenizerFast.__call__.return_tensors
class Tokenizing(Dataset):
# init 함수 생성
def __init__(self, data, model_name): # <python magic method> 객체 초기화
self.data = data # document, label로 구성된 dataframe 전달
self.tokenizer = BertTokenizerFast.from_pretrained(model_name) # Huggingface 토크나이저 생성
def __len__(self): # <python magic metho>, 내장함수 len() 를 구현하기 위해 호출, DataLoader가 처리할 총 배치의 수 return
return len(self.data) # tokenizing에는 필요없고, 추후에 progress bar를 위해 넣음
def __getitem__(self, idx): # <python magic method> self[key] 의 값을 구하기 위해 호출
sentence = self.data.iloc[idx]['document'] #iloc : dataframe 정수기반 위치 인덱싱
label = self.data.iloc[idx]['label']
# 토크나이징
tokens = self.tokenizer(
sentence, # 1개 문장
return_tensors='pt', # 텐서로 반환(종류 : tf-return tensorflow, pt-return pytorch, np-return numpy)
truncation=True, # 잘라내기 적용, default=False
padding='max_length', # padding 적용, default=False
add_special_tokens=True # 스페셜 토큰 적용, default=True -> 빼도 될듯
)
input_ids = tokens['input_ids'].squeeze(0) #2D->1D, [1,seq_length]->[seq_length]
# attention_mask : 패딩된 부분을 모델이 무시하도록 함
attention_mask = tokens['attention_mask'].squeeze(0)#2D->1D, [1,seq_length]->[seq_length]
# BERT는 두개 문장 입력시 0과1로 구분함. 위 코드로 어텐션마스크 크기만큼의 0텐서를 생성하여 모든 토큰이 하나의 문장(첫번째 문장)에 속한다는 것을 나타냄
token_type_ids = torch.zeros_like(attention_mask) # 단일문장 처리
return {
'input_ids' : input_ids,
'attention_mask' : attention_mask,
'token_type_ids' : token_type_ids,
}, torch.tensor(label)
3. 모델링
이제 진짜 실습의 키포인트!
모델은 허깅페이스의 kykim모델을 사용했다.
그 전에, 우리가 미리 만들어 놓았던 데이터를 DataLoader을 이용하여 Lapping 하도록 하자.
여기서 잠깐! DataLoader은 뭐고, 왜 이런 과정이 필요할까?
✅ DataLoader
: Neural Network는 batch단위로 학습을 하기 때문에, 데이터의 형태변화가 필요하다.
즉, batch_size * data shape 형태를 만들어 줘야하는데, 이를 자동적으로 해주는 것이 DataLoader!
한마디로 우리의 dataset을 Lapping해줘서 딥러닝 학습에 이용할 수 있도록 만들어주는 역할이라고 생각하면 된다.
1️⃣ CustomBert 만들어주기
앞서 구현한 Tokenizing으로 토큰화 된 train_data와 test_data를 DataLoader로 데이터 형태 변환을 해준다.
💡 batch_size, num_workers에 대해서
batch_size : 한번에 네트워크를 통과하는 데이터 샘플의 수, 일반적으로 32, 64, 128 등이 자주 사용됨
num_workers : 데이터 로딩에 사용되는 subprocess의 수, 종종 0부터 일반적으로 4, 8과 같이 설정됨

추가로, 데이터 형태를 살펴보고 싶어서 찍어보았다.
일단 입력으로 들어가는 x데이터의 구성은 다음과 같다. inputs.keys = dict_keys['input_ids', 'attention_mask', 'token_type_ids']
input.items()로 찍어볼 수 있는데, 첫번째는 item의 이름이 나오고 두번째는 item의 tensor가 나온다.
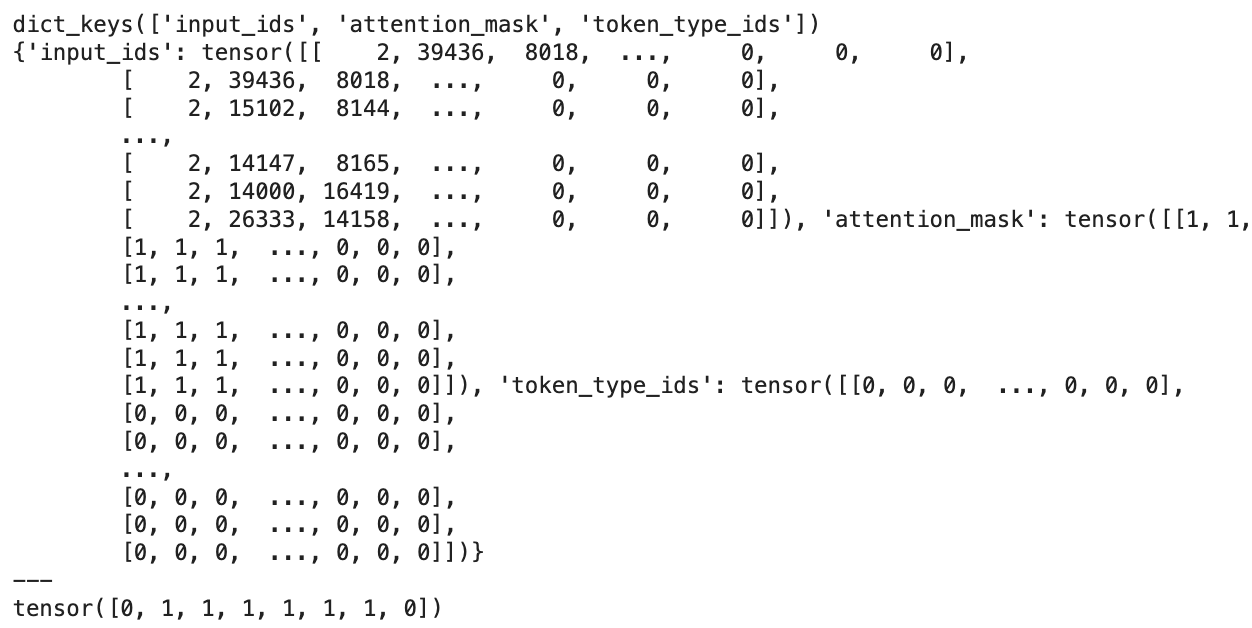
요런 느낌으로 생김. 맨 마지막은 레이블 형태. 신기하구만
BertConfig로 Bert 모델을 학습시키기 위한 요소들을 명시한 json을 확인해보자.
💡 Config란??
- batch_size, learning_rate 등 train에 필요한 요소들부터 tokenizer special token들을 미리 설정하는 등 설정에 전반적인 것들을 명시한다.
- saved_pretained 메소드를 이용하면 모델의 체크포인트와 함께 저장된다.
- huggingface의 PreTrained model을 그대로 사용하면 자동으로 config파일이 로드되어 명시할 필요가 없지만, 설정을 변경하고 싶거나 나만의 모델을 학습시킬 때에는 config 파일을 직접 불러와야한다.
- config도 model, tokenizer처럼 model ID만 있으면 config를 명확히 지정하거나 AutoConfig를 이용하는 방식으로 불러올 수 있다.

여기서 hidden_size를 기반으로 CustomBert를 만들것이다.
1개의 tensor를 빼서 모델에 넣은 결과를 output에 담아 key를 출력해보면 'last_hidden_state'와 'pooler_output' 이렇게 두개가 출력된다.
**input 형태
- last_hidden_state : 배치의 각 시퀀스에서 각 토큰에 대한 숨겨진 표현을 포함 (batch_size, seq_len, hidden_size)
- pooler_output : 배치의 각 시퀀스의 '표현'을 포함하며 (batch_size, hidden_size) 형태. 각 시퀀스의 [CLS] 토큰의 숨겨진 표현을 가져온 다음 BertPooler를 통해 실행하는 것으로 선형 레이어와 tanh 활성화 함수로 구성됨.
💡 드롭아웃(dropout) 이란?
: 신경망의 과적합 방지 기법 중 하나로, 훈련 과정에서 무작위로 일부 뉴런을 비활성화시키는 방법이다. (테스트나 평가시에는 적용X)
dropout_rate=0.5라면 각 훈련 단계에서 무작위로 50%의 뉴런을 비활성화시킨다.
< 드롭아웃의 주요 목적 >
- 과적합 방지 : 모델이 훈련 데이터에 지나치게 의존하는 것을 방지하여 일반화 능력을 향상시킴.
- 모델의 강인성 향상 : 뉴런의 비활성화로 인해 모델이 더욱 견고해지고, 다양한 특징을 학습할 수 있게 한다.
from transformers import BertModel
import torch
import torch.nn as nn
import torch.optim as optim
class CustomBert(nn.Module):
def __init__(self, model_name, dropout_rate=0.5):
# 부모 클래스 초기화
super(CustomBert, self).__init__()
# Pre-Trained 모델 지정
self.bert = BertModel.from_pretrained(model_name)
# dropout 설정하기
self.dr = nn.Dropout(p=dropout_rate)
# 최종 출력층 정의 (768,2)
# 768은 BERT모델의 'hidden_size'이며, 모델의 마지막 은닉층에서 나오는 특징 벡터의 차원수이다.
# 2는 최종적으로 분류하고자하는 클래스의 수를 의미한다.
self.fc = nn.Linear(768, 2)
def forward(self, input_ids, attention_mask, token_type_ids):
# 입력을 pre-trained bert model 로 대입
output = self.bert(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
# 결과의 last_hidden_state 가져옴
last_hidden_state = output['last_hidden_state']
# last_hidden_state[:, 0, :]는 [CLS] 토큰을 가져옴
x = self.dr(last_hidden_state[:, 0, :])
# FC 을 거쳐 최종 출력
x = self.fc(x)
return x
이제 custom bert 모델을 만들어줄 차례.
bert = CustomBert(model_name)
bert.cuda() # gpu에 올려준다
✅ loss function, optimizer 설정
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(bert.parameters(), lr=1e-5)loss function은 cross-entropy loss로 했고, optimizer는 adam을 사용했다.
2️⃣ 모델 훈련
앞서 progress bar로 출력해주기 위해 len을 정의해준것을 기억할 것이다. 여기서 쓸거다.
progress bar는 tqdm을 이용해서 불러올 수 있고, 이걸 안불러줘도 무관하지만 진행상황이 안보여서 답답할 수 있다.
inputs는 앞서 확인해 봤듯이 각 item의 이름과 item의 tensor들로 구성되어있다.
label은 그냥 tensor 형태의 레이블
모델 학습 과정은 다들 알겠지만 크게크게 forward -> backward -> optimize 순이다. 그리고 이 세개는 늘 같은 장치 위에 올라가 있어야 함!
미리 정의한 optimizer를 zero_grad로 파라미터 gradient를 초기화해주고 forward해준 뒤, loss를 구하고 역전파를 해준다.
이때, zero_grad의 위치는 zero_grad -> backward -> step 순서를 지켜준다면 상관없다!!
output.max(dim=1)의 반환값은 최대확률, 인덱스인데 모델이 잘 예측했는지 대조하기 위해 인덱스 값만 추출해준다.
추출한 인덱스와 레이블 값을 대조해주고 정확하게 맞춘 것만 corr 변수에 누적해준다.
loss에 batch_size를 곱해주면 batch 한개의 전체 loss값이 나온다.
이를 통해 loss값들을 누적하여 running_loss를 구해준다.
➡️ 구해준 corr변수와 running_loss를 전체 데이터셋 길이로 나눠 평균 loss와 최종 정확도를 산출해준다.
💡 **inputs ?
: python의 argument unpacking 문법으로, 딕셔너리 inputs의 key-value 쌍을 자동으로 풀어서(unpacking) 모델의 'forward' 함수에 전달한다. 모델에 여러 입력을 간편하게 전달하고자 할때 유용하고, 특히 BERT 같은 모델에 자주 사용된다.
from tqdm import tqdm
def train_model(model, data_loader, loss_fn, optimizer):
model.train()
running_loss = 0
corr = 0
counts = 0
# 보기좋게 progress bar로 출력. 안쓸거면 그냥 data_loader 밑에 넣으면 됨.
progress_bar = tqdm(data_loader, unit='batch', total=len(data_loader), mininterval=1)
# inputs과 labels 데이터 cuda에 올림
for idx, (inputs, labels) in enumerate(progress_bar): #progressbar 사용안하면 data_loader 바로 넣어주면됨.
inputs = {k:v.cuda() for k,v in inputs.items()}
labels = labels.cuda()
# zero_grad
optimizer.zero_grad()
# forward
output = model(**inputs)
# 손실함수로 손실 계산
loss = loss_fn(output, labels)
# backward(역전파)
loss.backward()
# 계산된 gradient 업데이트
optimizer.step()
# output.max(dim=1)은 output 각 행에서의 최대값을 찾음. 반환값 = 최대확률, 인덱스
# 여기서 잘 예측했는지 대조하기 위해 인덱스값만 쓸거임.
_, pred = output.max(dim=1)
# 예측한 index와 label을 대조하고, 정확하게 맞춘것만 .item()으로 tensor에서 값추출하고 corr 변수에 누적
corr += torch.sum(pred.eq(labels)).item()
# loss_fn(output, labels).item()으로 loss 값 추출
# labels.size(0) : batch_size
# loss * batch_size = 1개 배치의 전체 loss값.
# running_loss에 loss값들을 누적 -> 평균 loss 산출을 위함
running_loss += loss_fn(output, labels).item() * labels.size(0)
# 누적합들을 전체 데이터셋 숫자로 나눠 평균 loss와 최종 정확도를 산출
val_loss = running_loss / len(data_loader.dataset)
val_acc = running_loss / len(data_loader.dataset)
return val_loss, val_acc
3️⃣ 모델 평가 및 state_dict 저장
모델 평가 함수는 앞서 정의한 train과 거의 동일하다.
단지 model을 평가모드로 불러주고, 학습과정이 없을 뿐이다.
epoch는 너무 오래걸려서..ㅎㅎ 5로 해줬다.
loss 갱신될때마다 state_dict에 model을 업데이트해줬다.
최종적으로 stae_dict에 저장된 모델은 밑에서 .pth를 load해서 써주면 된다.
def evaluate_model(model, data_loader, loss_fn):
model.eval()
with torch.no_grad():
# loss와 accuracy 산출해야함
corr = 0
running_loss = 0
for inputs, labels in data_loader:
inputs = {k:v.cuda() for k,v in inputs.items()}
labels = labels.cuda()
# forward
output = model(**inputs)
# loss, accuracy 계산
_, pred = output.max(dim=1)
corr += torch.sum(pred.eq(labels)).item()
running_loss += loss_fn(output, labels).item() * labels.size(0)
loss = running_loss / len(data_loader.dataset)
acc = corr / len(data_loader.dataset)
return loss, acc4️⃣ 최종 모델 만들기 (토큰화 함수 + 모델 예측 + 확률 추출)
최종 모델을 만들어주는 클래스를 만들었다. (전처리-토큰화 + 모델 예측 합침)
그냥 보기 예쁘게 한번에 정리해준거다.
앞선 것처럼 init 함수 정의해주고, 토크나이저도 하이퍼 파라미터 지정해준다.
앞에 모델 훈련, 평가 때 처럼 prediction을 빼주고 softmax로 확률 형태를 얻는다.
그리고 가장 높은 확률의 인덱스를 추출해주기 위해 argmax를 이용한다.
그 뒤, 확률과 레이블을 출력해준다. prediction.max(dim=1)[0]에서 [0]은 앞에서 한번 본 적 있는데, 확률값과 인덱스를 반환하기 때문에 확률값만 쓰겠다는 뜻이다.
레이블은 미리 지정해준(뒤에 지정해줄거임) labels 딕셔너리에서 찾아서 할당한다는 것이다.
💡 dim=1은 각 예측벡터(각 클래스)에 대해 찾겠다는 것을 의미한다.
import torch.nn.functional as F
class CustomPredictor():
def __init__(self, model, tokenizer, labels:dict):
self.model = model
self.tokenizer = tokenizer
self.labels = labels
def predict(self, sentence):
tokens = self.tokenizer(
sentence,
return_tensors='pt',
truncation=True,
padding='max_length',
add_special_tokens=True
)
tokens = {k:v.cuda() for k,v in tokens.items()}
# tokens.to(device)
# tokens.cuda()
prediction = self.model(**tokens)
prediction = F.softmax(prediction, dim=1)
output = prediction.argmax(dim=1).item()
prob, result = prediction.max(dim=1)[0].item(), self.labels[output]
print(f'[{result}]\n확률은: {prob*100:.3f}% 입니다.')
state_dict에 저장한 내 모델을 불러와준다.
토크나이저를 지정해주고, 레이블 딕셔너리를 지정해준다. (원하는 출력값 지정)
앞에 정의해준 CustomPredictor을 생성해주면 정말 끝!!
💡 state_dict?
: 모델의 상태 사전(즉, 모델의 매개변수)로, 모델을 저장할 때 쓰인다.
모델 저장 방법에 대해 조금 더 알아보자면,
BERT와 같은 PyTorch 모델을 저장할 때는 일반적으로 pickle보다는 PyTorch의 내장함수인 torch.save를 사용하는게 권장된다.
torch.save는 모델의 매개변수를 효율적으로 저장하고 나중에 쉽게 불러올 수 있도록 도와준다. 아키텍처와 함께 모든 가중치를 저장하는데, 이 방법은 python 직렬화를 사용하므로 모델을 불러올 때 동일한 클래스 정의가 필요하다.
따라서, 상태사전만 저장하는 것이 더 유연하다. 모델의 구조가 변경되지 않는 한, 코드의 호환성을 더 잘 보장하므로 모델 아키텍처가 자주 변경되지 않는 경우 상태사전을 저장하는 방법을 더 권장한다고 한다!
# 저장한 state_dict를 bert 모델에 load -> 진짜 내 모델!!
bert.load_state_dict(torch.load(f'{my_model}.pth'))
tokenizer = BertTokenizerFast.from_pretrained(model_name)
labels = {
0: '부정 리뷰 입니다.',
1: '긍정 리뷰 입니다.'
}
predictor = CustomPredictor(bert, tokenizer, labels)
한번 예측을 해보자!!

굳굳..
잘 분류하는 것 같다!!
이상으로 BERT 네이버 영화 리뷰 감정분류 실습을 마치겠다!
더 다양하게 여러 감정으로 나눠서 분류하는 방식도 해보면 재밌을 것 같다. 그러면 전처리가 추가적으로 필요하겠다.
일단 다음엔 (아마) GPT 모델 실습으로 돌아오겠다 〰️〰️
----
[참고]
https://teddylee777.github.io/huggingface/bert-kor-text-classification/
'ML > NLP' 카테고리의 다른 글
| [NLP] BERT에 대해서 (1) | 2024.01.06 |
|---|---|
| [NLP] LLM이란? (0) | 2024.01.05 |