이전 포스팅에 이어 RMSProp과 Adam에 대해 계속해서 알아보겠다!
📌 Gradient Descent Algorithm이란?
📌 Batch gradient descent에 대해서
< 잠깐, 📌 SGD(Stochastic gradient descent)란? >
< local minimum과 이것을 피하기 위한 방법들 >
--- momentum 이용
1️⃣ Momentum
2️⃣ Nesterov Momentum
--- learning rate 이용
3️⃣ AdaGrad
(NEW!) 지수가중이동평균이란?
4️⃣ RMSProp
5️⃣ Adam
RMSProp를 알기 이전에 "지수가중이동평균"에 대해 알아야한다.
💡 지수가중이동평균이란?
이전의 값과 현재의 값에 다른 가중치 (두 가중치의 합은 1)를 주는 방식이다.

이 식에서 β가 Hyper parameter이고, 보통 0.9를 사용한다.
β=0.9일때, 이전값(최근값들)인 Vt-1에 더 많은 가중치를 주고, 현재 값인 세타t에는 작은 가중치를 주게 된다.
β값이 클수록 선이 더 부드러워진다. 왜냐면 더 큰 범위의 값들을 평균화하기 때문!
❓ 왜 지수가중이동평균을 사용할까?
지수가중이동평균은 최근 데이터에 더 많은 영향을 받는 데이터들의 평균 흐름을 계산하기 위해 구한다.
그리고 최근 데이터 지점에 더 높은 가중치를 준다.
우리가 오늘 알아볼 RMSProp가 이 지수가중이동평균을 사용한다.
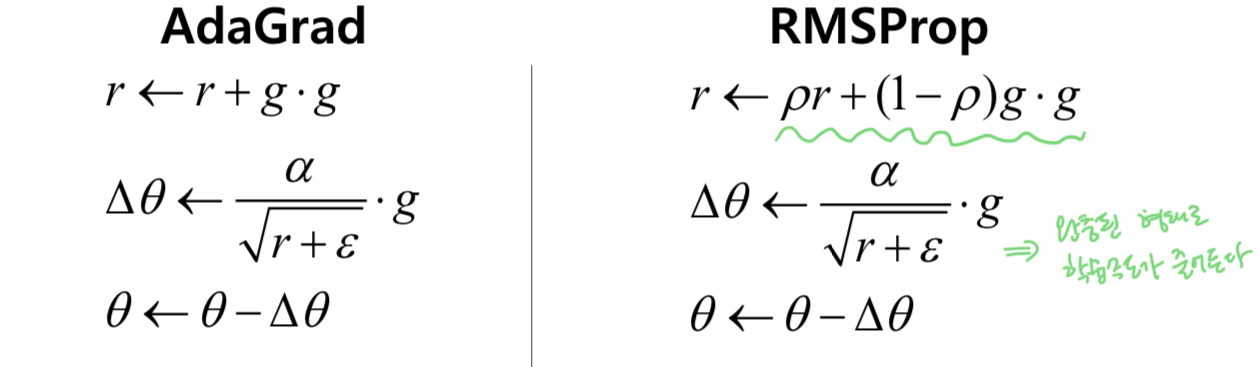
간단하게, AdaGrad의 r값에 지수가중이동평균을 적용해주면 된다.
적용 방식에 대해 간단히 알아보자!

그래서, RMSProp는 미분값이 큰 곳에서 업데이트 할 때 큰 값으로 나눠주기때문에 기존 학습률보다 작은 값으로 업데이트를 해준다.
이는 진동을 줄이는데 큰 도움이 된다.
반면 미분값이 작은 곳에서는 작은 값으로 나눠주기 때문에 기존 학습률보다 큰 값으로 업데이트 해준다.
이는 앞서 제기되었던 조기 종료 문제를 막으면서도 더 빠르게 수렴하는 효과 또한 일으킨다.
그렇다면 여기서 RMSProp의 단점은 무엇일까?ㅎㅎ
바로 출발 지점에서 멀리 떨어진 곳으로 이동하는 초기 경로의 편향문제이다.
초기경로에서 편향문제는 왜 발생할까?

훈련을 시작할 때 1차 관성 v0, 2차 관성 r0을 0으로 초기화한다.
이상태에서 첫번째 단계를 시행하면 각각 0.1, 0.01이 곱해져 값이 매우 작아지게 된다.
때문에 r이 작아지면 적응적 학습률이 매우 커져 출발 지점에서 멀리 떨어진 곳으로 이동을 하게 되고,
이는 최적해에 도달하지 못할 수도 있다.
5️⃣ Adam
이번엔 최근 가장 활발히 사용되는 Adam(Adaptive moment estimation)에 대해 알아보겠다.
Adam은 RMSProp에 이전 포스팅에서 알아봤던 Momentum을 합친 방식이다.
즉, 진행하던 속도에 '관성'도 주고 최근 경로의 '곡면 변화량에 따른 적응적 학습률'을 가지는 알고리즘이다.
Adam은 첫번째 moment를 momentum으로부터 계산하고, 두번째 moment를 RMSProp으로부터 계산한다.
Adam은 매우 넓은 범위의 아키텍쳐를 가진 서로 다른 신경망에서 잘 작동되는 것이 증명되어서 현재 일반적으로 가장 많이 사용된다.
RMSProp의 초기 경로의 편향 문제점을 개선시켰는데, 그 방식은 다음과 같다.

개선된 s,r로 수식을 진행해보면 결국 식이 상쇄되기 때문에 아주 작아질 일이 없게 된다.
또한 Adam은 이전까지 본 방법들과 다르게 hyper parameter가 많다는 특징이 있는데, 뭐가 있는지 보자.
- α : learning rate(학습률), 다양한 값을 시도해서 잘 맞는 값을 찾아야 함
- β1 : 기본적으로 0.9 사용. Momentum에 관한 항
- β2 : 기본적으로 0.99나 0.999를 사용. (0.999를 추천한 논문이 있다고 함)
- ϵ : 분모가 0이되는 것을 막기 위한 상수, 설정하지 않아도 전체 성능에 영향이 없음. (Adam 논문에서 10^-8을 추천했다고함)
지금까지 Optimizer의 종류에 대해 알아보았다.
다른 여러 종류의 Optimizer들이 많지만, 그중 대표되는 것들에 대해 알아보았던 시간이었다.
[참고]
'ML' 카테고리의 다른 글
| 유의미한 변수 선택하는 방법 (RFE, RFECV) (0) | 2024.04.02 |
|---|---|
| 경사하강법(Gradient Descent Algorithm)과 Optimizer 종류 정리 1️⃣ (0) | 2024.01.27 |
| 차원의 저주(Curse of Dimension)와 차원축소 (2) | 2024.01.25 |
| Bias-Variance Trade-off (0) | 2024.01.24 |
| [Error] CUDA error: invalid device ordinal 해결방법 (0) | 2024.01.18 |