이번 포스팅에서는 한번쯤은 들어봤을 법한 차원의 저주(Curse of Dimention)와 차원축소 방법들에 대해서 알아보겠다.
차원의 저주란?
간단히 말해 데이터의 차원이 증가할수록 모델의 성능이 저하되는 현상이다.
단순히 데이터 변수의 수가 증가하는 것이 아닌, 관측치 수보다 변수의 수가 많아지는 상황을 말한다.
차원의 저주가 그래서 정확히 뭘 말하는 걸까?
예를 들어, 1차원 데이터에 5개의 샘플이 있을 때, 이때 하나의 샘플은 전체 데이터에서 1/5의 밀집도를 가질 것이다.
여기서 만약 데이터가 2차원일때 하나의 샘플은 5*5 전체에서 1/25의 밀집도를 가지게 된다.
데이터가 3차원이라면? 하나의 샘플은 1/125의 밀집도를 가질것이다.
즉, 차원이 증가할수록 데이터의 밀집도는 줄어들고, 빈공간이 많아지며 필요한 데이터의 양은 지수적으로 (기하급수적) 증가한다.
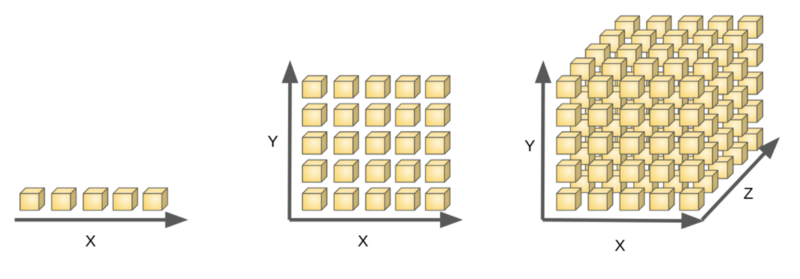
결과적으로 데이터의 샘플들 사이 거리는 증가하게 된다.
이것은 Euclidean Distance와 같은 metric을 사용할 때 왜곡이 매우 심해져 metric이 제대로 동작하지 못하는 문제를 초래할 수 있다.
또한 차원이 증가할 수록 처리할 데이터에 대한 시간 및 공간 복잡도 또한 증가하여 효율성이 매우 떨어지게된다.
그렇다면 이런 차원의 저주를 어떻게 해결할까?
바로 차원을 축소하는 것이다.
차원 축소 기법이란?
: 차원축소란 매우 많은 피처로 구성된 다차원 데이터 세트의 차원을 축소하여 새로운 저차원의 데이터 세트를 생성하는 것이다.
- 차원이 증가할수록 데이터 간의 거리가 기하급수적으로 증가 → 희소한 구조형태, 모델의 예측 신뢰도 하락
- 차원축소시 학습 데이터의 크기가 줄어 학습에 필요한 처리 능력도 ⬇️
- 단순히 데이터를 압축하는 것이 아닌 데이터를 더 잘 설명할 수 있는 요소를 추출하는 개념
- 과적합 방지와 숨겨진 의미 추출 등의 역할을 할 수 있음
- 피처 선택(Feature Selection)과 피처 추출(Feature Extraction)로 나눔
피처 선택 : 특정 피처에 종속성이 강한 불필요한 피처는 제거하는 것
- 장점 : 선택한 피처의 해석이 용이
- 단점 : 피처간 상관관계 고려가 어려움
피처 추출 : 기존 피처를 저차원의 중요 피처로 압축하여 추출하는 것. 기존의 피처가 압축된 형태로 기존 피처와는 완전 다른 값이 됨
- 장점 : 피처 간 상관관계 고려가 용이, 피처 개수를 많이 줄일 수 있음
- 단점 : 추출된 변수의 해석이 어려움
PCA
: 가장 대표적인 차원 축소 기법으로, 여러 변수 간 존재하는 상관관계를 이용하여 이를 대표하는 주성분을 추출해 차원을 축소하는 기법
🔅 핵심 - 데이터를 축에 사영했을 때 가장 높은 분산을 가지는 데이터의 축을 찾아 그 축으로 차원을 축소하는 것.
이 축을 주성분이라고 함.
❔이유는 정보의 손실을 최소화 하기 위해서!
❕왜냐하면 사영했을 때 분산이 크다는 것은 원래 데이터의 분포를 잘 설명할 수 있다는 것을 뜻하기 때문에, 정보의 손실을 최소화 할 수 있다!


PCA는 제일 큰 분산을 첫번째 축으로, 두번째 축은 첫번째 축에 직각이 되는 벡터를, 세번째 축은 다시 두번째 축과 직각이 되는 벡터를 축으로 설정하는 방식으로 축 설정을 한다.
이렇게 생성된 벡터 축에 원본 데이터를 투영하면 벡터 축의 개수만큼의 차원으로 원본 데이터가 차원축소 된다.
❓ 직각이 되는 벡터를 다음 축으로 설정하는 이유는?
< 예시와 함께 알아보기>
첫번째 축에 데이터를 사영했는데 같은 점으로 겹쳐 사영된 데이터가 10개가 있다고 가정해보자. (축에 겹쳐지는 데이터가 10개라는 뜻)
첫번째 축으로는 이 10개의 데이터를 모두 설명할 수 없기 때문에 다른 축이 필요하다.
이때, 직교하는 축으로 사영하게 되면 겹쳤던 10개의 데이터는 절대 같은 점으로 사영될 수 없고 두번째 축이 이 10개의 데이터를 설명할 수 있게 된다.
이런 원리로 계속 직교하는 축을 다음 축으로 설정하는 방식으로 축 생성하는 것!
❓축을 찾는 방법?
: 입력 데이터의 공분산 행렬을 고유값 분해했을 때 구해진 고유벡터가 PCA의 주성분 벡터로서 입력 데이터의 분산이 큰 방향을 나타낸다.
고유값이 고유벡터의 크기를 나타내고 입력 데이터의 분산을 나타낸다.
✅ PCA 진행 순서
- 입력데이터 세트의 공분산 행렬을 구한다.
- 공분산 행렬을 고유값 분해하여 고유벡터와 고유값을 구한다.
- 고유값이 가장 큰 순으로 K개 (변환차수)만큼 고유벡터 추출
- 고유벡터에 입력데이터를 선형 변환
PCA과정 수행을 위해서는 각 피처의 평균과 편차를 일정하게 맞추는 정규화 과정이 필수적으로 수행되어야하기 때문에, StandardScaler를 적용해준다.
[참고]
https://gannigoing.medium.com/pca-principal-component-analysis-6b9d4410d6c1
'ML' 카테고리의 다른 글
| 경사하강법(Gradient Descent Algorithm)과 Optimizer 종류 정리 2️⃣ (1) | 2024.01.28 |
|---|---|
| 경사하강법(Gradient Descent Algorithm)과 Optimizer 종류 정리 1️⃣ (0) | 2024.01.27 |
| Bias-Variance Trade-off (0) | 2024.01.24 |
| [Error] CUDA error: invalid device ordinal 해결방법 (0) | 2024.01.18 |
| [Colab] matplotlib 한글폰트 깨짐 현상 해결 mac (0) | 2023.12.19 |